Elasticsearch
搜索功能几乎是Web1.0以来最重要、普遍而又复杂的一个功能了。
对于关系型数据库数据的查询,只能应付诸如数值比较、范围过滤这些比较简单的需求。再复杂一点的情况,关系型数据库就显得有些力不从心了。
虽然关系型数据库与NoSQL之间走得越来越近,MySQL从5.6开始支持全文索引、从5.7.6开始支持中文全文索引,但对比起来,Elasticsearch无论在生态、搜索能力上,都更出色。
指南
文档较旧,本文的语法部分更新为新的了
Elasticsearch是面向文档的。
元数据元素
| 关系型数据库 | Elasticsearch |
|---|---|
| database | null |
| table | index |
| null | type(deprecated) |
| row | document |
| column | field |
| schema | mapping |
| index(B+) | inverted index(LSM) |
| SQL | Query DSL |
当索引表示一个动词的时候表示将文档放到index中。
写操作
在Elasticsearch中,每个字段的所有数据都是默认被索引的。
PUT操作需要全量更新。如果_id不存在,就解释为POST。部分更新通过POST /blog/_update/1实现。
同时文档是不可变的,更新内部采用CopyOnWrite的方式进行。
PUT /blog/_doc/1?version=1实现乐观锁。
分布式
支持调整副本数,不支持调整分区。
路由算法:shard = hash(routing) % number_of_primary_shards
routing默认为_id,可通过请求的routing参数进行自定义。
搜索
字段
在索引时,Elasticsearch首先分析文档,之后根据结果创建倒排索引(inverted index),进而实现搜索。
这个倒排索引除了保存词项出现过的文档列表,还会保存每一个词项出现过的文档总数,在对应的文档中一个具体词项出现的总次数,词项在文档中的顺序,每个文档的长度,所有文档的平均长度,等等。
映射(mapping、模式定义),能够将时间域视为时间,数字域视为数字。 如果域是未预先定义的,那么会被动态映射。
当索引一个文档的时候,Elasticsearch取出所有字段的值拼接成一个大的字符串,作为_all字段进行索引(新版本已移除这种特性)。 而每个字段的值都被添加到自己的倒排索引中。
text域映射的两个最重要属性是index和analyzer。
{
"tag": {
"type": "text",
"index": true,
"analyzer": "standard"
}
}
- true 首先分析字符串,然后索引它。
- false 不索引这个域。
- 不分析,但索引:
{ "tag": { "type": "keyword" } }
复杂类型
简单类型数组与单个值类型相同。
对于object域内部的域,Elasticsearch内部转化成user.name这样来表示。
multi-fields:
It is often useful to index the same field in different ways for different purposes. This is the purpose of multi-fields. For instance, a string field could be mapped as a text field for full-text search, and as a keyword field for sorting or aggregations:
类型为text的、被分析的字段可能需要按不分析来排序,可以映射为
"tweet": {
"type": "text",
"analyzer": "english",
"fields": {
"raw": {
"type": "keyword"
}
}
}
并在搜索时引用"sort": "tweet.raw"。
搜索
POST /megacorp/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}
- 检查字段类型 分析域(text)意味着查询字符串被应用相同的分析器(分词、标准化等)。
- 分析查询字符串 将查询的字符串传入分析器中(可以与索引的分析器不同),而查询一个精确值域时,不会分析查询字符串。
- 查找匹配文档 查询在倒排索引中查找结果的每个词,然后获取一组文档。
- 为每个文档评分 计算每个文档相关度评分 _score 。
搜索分为:
- 过滤 上面的栗子中用filter包裹的部分,不参与评分,可以缓存,通常用在精确值域
such as the filter or must_not parameters in the bool query, the filter parameter in the constant_score query, or the filter aggregation.
- 查询 匹配有相关性的文档,参与评分,不被缓存
排序
默认排序是_score降序,使用sort参数可以改变。
如果字段有多个值(如数组),最好利用函数将多值字段减为单值以便于排序的进行。 被分析的字符串字段也是多值字段。
分布式检索
因文档分区是跨机器的,执行检索时必须用到逻辑分页:
搜索需要一种更加复杂的执行模型因为我们不知道查询会命中哪些文档: 这些文档有可能在集群的任何分片上。 一个搜索请求必须询问我们关注的索引(index or indices)的所有分片的某个副本来确定它们是否含有任何匹配的文档。
但是找到所有的匹配文档仅仅完成事情的一半。 在 search 接口返回一个 page 结果之前,多分片中的结果必须组合成单个排序列表。 为此,搜索被执行成一个两阶段过程,我们称之为 query then fetch 。
算法如下:
- 查询阶段
- 客户端发送一个 search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
- Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
- 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点,也就是 Node 3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 这个阶段需要缓存大量的匹配文档,对结果排序的成本随分页的深度成指数上升,即使我们只需要pageSize个全局的结果,也必须将每个分片的前pageNo * pageSize结果查询出来。
- 取回阶段
- 协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。
- 每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。
- 一旦所有的文档都被取回了,协调节点返回结果给客户端。
存在一种优化算法,将查询阶段分为预查询(得到一个估计值)与二次查询(得到修正值),能够有效减少数据量。
对于不需要排序的查询,Elasticsearch的"sort" : ["_doc"],可以以GET /old_index/_search?scroll=1m的方式来优化查询。
分页普遍出现在各种应用程序中,在通常的优化手段包括:
- 禁止跳页,通过上一页最后一条数据定位本页数据
- 允许数据精度损失等其它业务可接受的折衷,然后应用相应的算法
部署
Docker Hub中有官方提供的镜像。部署模式是单机。建议用7.X版本,Flink驱动还没有8.X版本的。 官方文档
docker run -p 127.0.0.1:9200:9200 -p 127.0.0.1:9300:9300 -e "discovery.type=single-node" --name ecstatic_jang --network docker_default docker.elastic.co/elasticsearch/elasticsearch:7.17.9
docker run --name kib01-test --network docker_default -p 127.0.0.1:5601:5601 -e "ELASTICSEARCH_HOSTS=http://ecstatic_jang:9200" docker.elastic.co/kibana/kibana:7.17.9
Flink
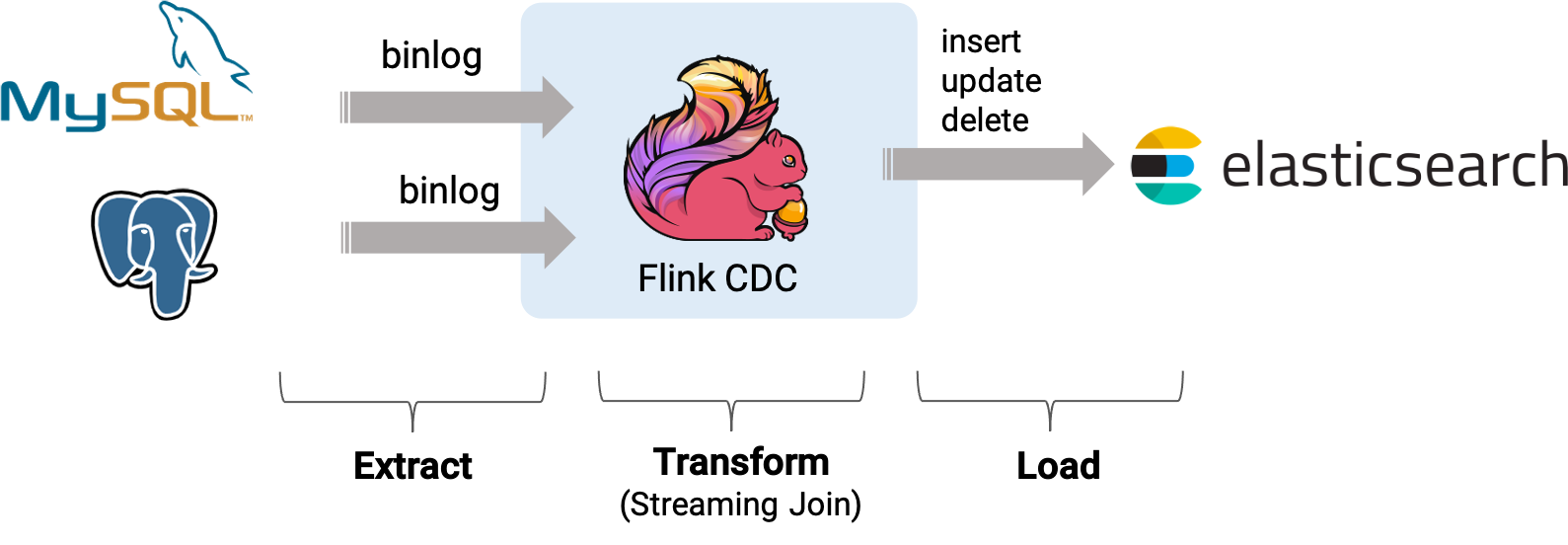
准备测试数据
略
准备连接
- 下载flink-sql-connector-mysql-cdc、flink-sql-connector-elasticsearch7
- 创建用户
CREATE USER 'user'@'localhost' IDENTIFIED BY 'password'; - 授权
GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user'@'localhost'; FLUSH PRIVILEGES;- Flink只支持RBL
set global binlog_format='ROW';
部署Flink
version: "2.2"
services:
jobmanager:
image: flink:1.16.0-scala_2.12
ports:
- "8081:8081"
command: jobmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager:
image: flink:1.16.0-scala_2.12
depends_on:
- jobmanager
command: taskmanager
scale: 1
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager.numberOfTaskSlots: 2
运行客户端
docker cp flink-sql-connector-*.jar docker_jobmanager_1:/opt/flink/lib/
docker cp flink-sql-connector-*.jar docker_taskmanager_1:/opt/flink/lib/
docker exec -it [CONTAINER] /bin/bash
./bin/sql-client.sh
Flink SQL> SET execution.checkpointing.interval = 3s;
Flink SQL> CREATE TABLE request (
id INT,
consumer STRING,
request_id STRING,
consumer_origin STRING,
request_id_origin STRING,
status STRING,
version INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'docker.for.mac.localhost',
'port' = '3306',
'username' = 'user',
'password' = 'password',
'database-name' = 'idempotent',
'table-name' = 'request',
'server-time-zone' = 'Asia/Shanghai'
);
Flink SQL> CREATE TABLE consumer (
id INT,
consumer STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'docker.for.mac.localhost',
'port' = '3306',
'username' = 'user',
'password' = 'password',
'database-name' = 'idempotent',
'table-name' = 'consumer',
'server-time-zone' = 'Asia/Shanghai'
);
Flink SQL> CREATE TABLE enriched_request (
id INT,
consumer STRING,
description STRING,
request_id STRING,
consumer_origin STRING,
description_origin STRING,
request_id_origin STRING,
status STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://ecstatic_jang:9200',
'index' = 'enriched_request'
);
Flink SQL> INSERT INTO enriched_request
SELECT r.id, r.consumer, c1.description, r.request_id, r.consumer_origin, c2.description,
r.request_id_origin, r.status
FROM request AS r
LEFT JOIN consumer AS c1 ON r.consumer = c1.consumer
LEFT JOIN consumer AS c2 ON r.consumer_origin = c2.consumer;
流处理理论
名词解释
- HDFS Hadoop框架的分布式文件系统
- MapReduce(狭义) Hadoop中执行map和reduce的引擎
- Hive MapReduce的高层接口(SQL)
- HBase 运行在HDFS之上的一种NoSQL
- Spark 另外一种计算引擎,被Hive支持,性能较MapReduce好,同时有自己的SQL API,Spark SQL同时支持操作Hive
- Flink 更加新颖的一种(流)计算引擎,如上面中的栗子
资料
在豆瓣上搜最高分的有松鼠书。
松鼠书也有一些没有的内容,如批处理、Table API 见官方文档 https://nightlies.apache.org/flink/flink-docs-release-1.16/zh
推荐阅读顺序
- 执行模式(流/批) https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/datastream/execution_mode/
- 动态表 (Dynamic Table) https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/concepts/dynamic_tables/
- 概念与通用 API https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/common/
- 时间属性 https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/concepts/time_attributes/
- DataStream API Integration https://nightlies.apache.org/flink/flink-docs-release-1.16/zh/docs/dev/table/data_stream_api/